Giving structure to your Kubernetes configuration
March 28, 2022
The more complex your Kubernetes clusters become, the more you benefit from a good structure for the Kubernetes configuration. It keeps it maintainable, promotes re-use, and makes it easy to understand for everyone.
Kustomize
Kubernetes offers Kustomize as “a template-free way to customize application configuration”. It focuses on declarative configuration management and relies only on yaml files. By using patches, you can adjust certain parameters for a specific deployment or environment. I’m a big fan of declarative configuration management because you describe the desired state, and you don’t have to worry about how to get to that desired state.
Separating shared services from project-specific deployments
In every Kubernetes cluster you have shared services like the NGINX ingress, certificate manager, operators, etc. I always separate the deployment of those services from the project-specific deployments by putting them in a different project with its own deployment lifecycle. By doing that, you prepare yourself for when you’re going to deploy more than one project to the Kubernetes cluster. And it’s also a nice place to store the Infrastructure as Code configuration for provisioning the Kubernetes cluster.
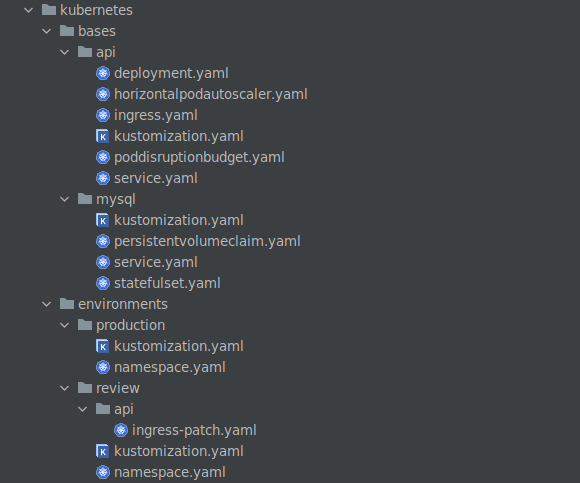
Folder structure
Kustomize has the concept of bases and overlays.
Instead of an overlays folder, I like to name that folder what it actually is.
For the shared services project, this folder is to differentiate between the Kubernetes clusters. You can have one
cluster that holds all projects and environments, or multiple clusters. I prefer to create one Kubernetes cluster for
development purposes; this will contain the dev, test, qa, staging and review environments, and one cluster for
production only.
By having a development and production cluster, you can test the changes you make in the Kubernetes config on the
development clusters first before rolling them out to your production cluster.
Shared services
In this example, we have the NGINX ingress which is responsible for routing all incoming traffic to the right service. And we have the cert-manager, which makes sure we have valid TLS for every ingress.
This brings us to the following folder structure;
kubernetes/
├ bases/
│ ├ nginx-ingress/
│ ├ cert-manager/
│ └ kustomization.yaml
└ environments/
└ production/
└ kustomization.yaml
└ development/
└ kustomization.yaml
Project-specific deployments
The example project that we want to deploy consists of an API app and a MySQL database. We have two environments; a review environment and a production environment. That’s reflected in the names of the overlays.
kubernetes/
├ bases/
│ ├ api/
│ ├ mysql/
│ └ kustomization.yaml
└ environments/
└ production/
└ kustomization.yaml
└ review/
└ kustomization.yaml
The bases should target production
When you have multiple environments re-using the same bases, I recommend for the bases to
target the production environment. That is the main environment; the other environments are derivatives of the
production environment. This means the environments/production folder shouldn’t have any patches.
Variable substitution
Kustomize doesn’t have a way to do variable substitution. They have their reasons,
and that’s fine, but in reality, you need some way to modify the manifests during the deploy jobs in the CI/CD
pipeline. You probably want some secrets to be replaced with values from the secrets stored in the CI/CD pipeline.
And, if you use review apps, you’ll want to give every environment a unique URL. So the ingress needs to be dynamic as
well. Kustomize doesn’t have any functionality for this, so what I do is use envsubst
to replace $VARIABlE with the value that is present in the environment.
The deployment job looks like this;
cd kubernetes/environments/production
find . -iname \*.yaml -type f -exec sh -c 'envsubst < $0 > $0.tmp && mv $0.tmp $0' {} \;
kubectl apply -k .
This will step into the environment folder, find all yaml files and replace any variable it encounters with the value set as an environment variable.
To avoid using variables all over the place, I have one important rule;
It’s only allowed to use variables in the configuration inside the environment (overlay) folder
That means that if you want to make the ingress dynamic with a variable, you need to create a patch file in the
environments/review folder and use the variable there.
For example;
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: api
spec:
rules:
- host: $ENVIRONMENT_DOMAIN
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: api
port:
name: http
Be aware that envsubt will try to replace any value that looks like a variable ($SOMETHING). You can limit its
scope by giving the variables it should replace as arguments.