The key components of Kubernetes autoscaling
September 5, 2021
Autoscaling is an important feature of Kubernetes. With this feature, you always have enough resources for the workload, and when a node becomes unhealthy it gets replaced without affecting the workload. But you won’t get it automatically by just deploying your Pods on Kubernetes.
You need to provide the scheduler with information about your Pods, so it can make the right decisions when scheduling them.
A scheduler watches for newly created Pods that have no Node assigned. For every Pod that the scheduler discovers, the scheduler becomes responsible for finding the best Node for that Pod to run on.
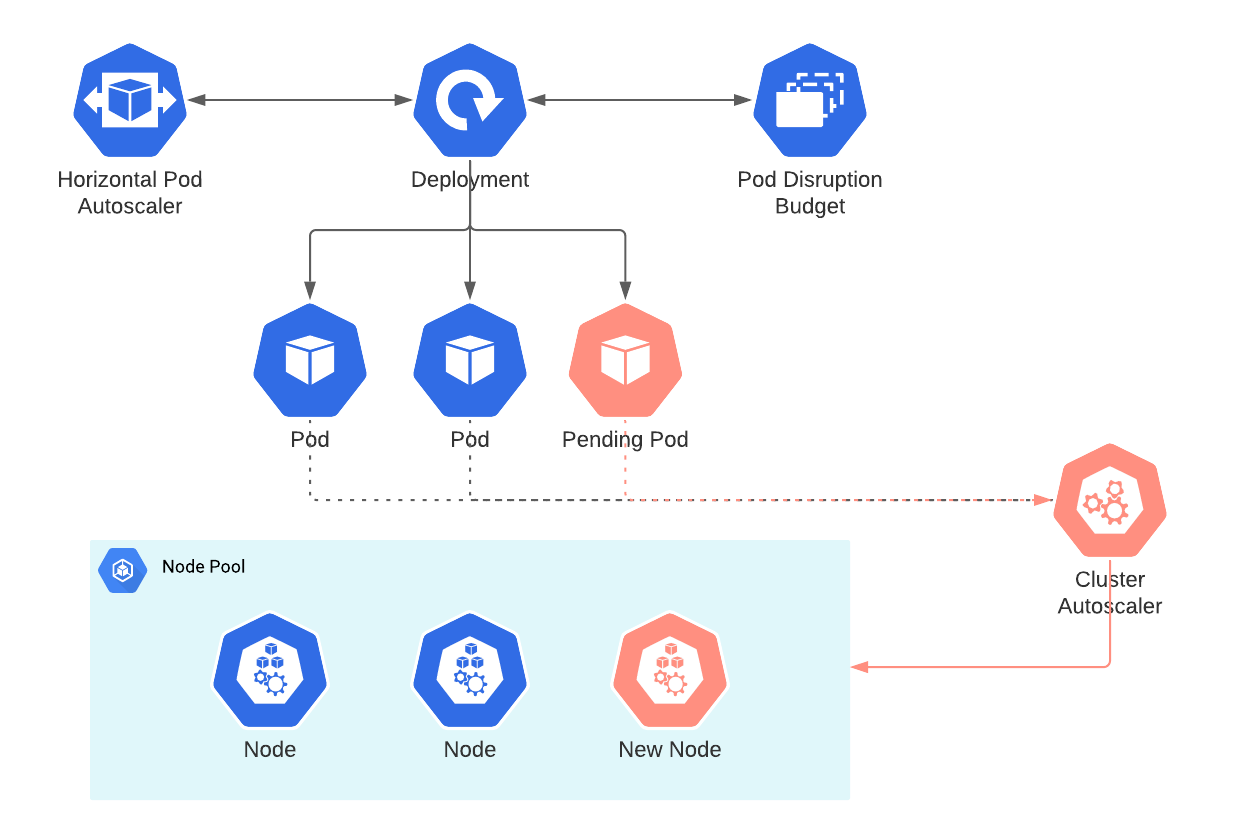
The following components are needed to truly benefit from the autoscaling feature of Kubernetes;
They work together as shown in the following diagram. Each component is explained in the next chapters.
Resource Request
When you configure a Pod, you specify how much of each resource it needs. The most common resources to specify are CPU and memory, but there are others.
Per Pod you can specify;
- The amount of CPU & memory you expect this Pod needs; the request
- The amount of CPU & memory you’re allowing the Pod to use; the limit
The scheduler takes the resource request into account when determining which node has the resources available to run this Pod. When there is not a node available that would fit the Pod’s resource request, the Pod goes to the Pending state.
The Cluster Autoscaler will notice a Pod is pending because of a lack of resources and acts upon it by adding a new node.
Configuring the resource request
The resource request is configured per Pod like this;
resources:
requests:
cpu: "200m"
memory: "128Mi"
To come up with sane values for CPU & memory you can take the following into account;
kubectl top pods -Ashows the actual CPU & memory usage of all Pods. Be aware that this is a snapshot of that moment, it’s better to gather this information from a monitoring system that can show the trend over a longer period.- CPU is a resource that can overbooked, if the actual usage is higher than defined in the resource request then this could result in performance issues but the Pod wouldn’t get evicted because of it.
- Memory can’t be overbooked and is reserved based on the resources request. When a Pod is using more memory than configured and the node runs out of memory the scheduler could evict this Pod.
Pod Disruption Budget
Pod disruption budgets allow you to configure the number of Pods that can be down simultaneously from voluntary disruptions. Voluntary disruptions are mostly triggered by the application owner or cluster administrator. This happens for example when a deployment is changed or a node is drained. The scheduler makes sure that when it’s evicting Pods, it keeps enough Pods running from the same deployment, statefulset or other controllers to don’t exceed the Pod disruption budget.
The cluster autoscaler is performing cluster administrator actions like draining a node to scale the cluster down. That’s why it’s important to configure these correctly when you want the cluster to autoscale and auto-heal.
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: myapp
spec:
maxUnavailable: 1
selector:
matchLabels:
app: myapp
Example of a Pod Disruption Budget that allows for 1 Pod to be unavailable at the same time.
Horizontal Pod Autoscaler
With a Horizontal Pod Autoscaler, you specify which metrics decide if the number of replicas should scale up or down. You can use per-Pod resource metrics like CPU and memory or custom metrics like the number of requests/second, the Pod is receiving.
Resource metrics can be defined as utilization value, e.g.;
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 90
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 90
When you define the metric as utilization value it will be calculated as the percentage of the configured resource request.
Let’s say you have a Pod with 1 CPU and 1 GiB memory configured as resource requests. With the Horizontal Pod Autoscaler configured as in the example it will scale up when the Pod is using 900m CPU or 900 MiB memory.
Cluster Autoscaler
The Cluster Autoscaler is the component that adjusts the size of the node pool so that all Pods have a place to run and there are no unneeded nodes.
On most public cloud providers it’s part of the control plane which is managed by the provider. For AWS that’s not the case, you need to deploy it yourself.
Adding a node
The Cluster Autoscaler will monitor the Pods and decide to add a node when a Pod needs to be scheduled and there aren’t sufficient resources for the resource request of that Pod.
This works as follows;
- A new Pod is created
- The scheduler reads the resource request of the Pod and decides if there are enough resources on one of the nodes.
- If there are, the Pod is assigned to the node.
- If there aren’t, the Pod is set to the Pending state and can’t start.
- The Cluster Autoscaler will detect a Pod is not able to schedule due to a lack of resources.
- The Cluster Autoscaler will determine if the Pod could be scheduled when a new node is added (it could be due to (anti-) affinity rules that the Pod still can’t schedule on the newly created node).
- If so, the Cluster Autoscaler will add a new node to the cluster.
- The scheduler will detect the new node and schedule the Pod on the new node.
It’s important to know that the scheduler is not capable of moving Pods to different nodes to make room for the new Pod. This can sometimes lead to inefficient use of resources.
Removing a node
The Cluster autoscaler will decide to remove a node when it has low utilization and all of its important Pods can be moved to other nodes. There are a few reasons which prevent a Pod from being moved to a different node. To move a Pod it needs to be evicted and a new one needs to be started on a different node.
Reasons why a Pod can’t be moved;
- The Pod has a restrictive Pod Disruption Budget.
- The Pod is part of the kube-system namespace and doesn’t have a Pod Disruption Budget, or it’s too restrictive.
- The Pod isn’t backed by a controller object (so not created by deployment, replica set, job, statefulset, etc.).
- The Pod has local storage and doesn’t have the safe-to-evict annotation.
- The Pod can’t be moved due to various constraints (lack of resources, non-matching node selectors or (anti-) affinity, safe-to-evict annotation set to false, etc.)
The logs of the Cluster Autoscaler can tell you the actual reason, but when the Cluster Autoscaler is managed by the cloud provider you don’t always have access to that log.
If you think a node could be removed and the Cluster Autoscaler is not acting on it, you could try to drain the node and see what output that gives. In some cases, this will show the reason why the Cluster Autoscaler can’t remove it, for example when the Pod Disruption Budget doesn’t allow it.
Go back